

When data turns into disaster
We live in a digital world where data is a critical constituent for business. But sometimes a disaster event affects good data.
Disaster may come in all forms and sizes and may happen due to multiple reasons: natural disasters, hardware failures, human errors (inadvertent or unauthorized modifications) or cybercrimes. Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified as a disaster.
In Google Cloud’s Architecture Framework, the “Reliability” pillar provides sets of practices, guidelines and recommendations on how to architect and operate reliable services on Google Cloud. This helps customers to be prepared for disaster events.
Disaster recovery planning
When talking about disaster recovery and business continuity it can be easy to fall under the impression that these terms represent the same thing. Well, is there any difference?
The short answer — yes, there is! Disaster recovery is a subset of business continuity planning.
- Disaster recovery (DR) revives the company’s operations and processes once disaster strikes. It is about bringing things back (e.g. applications) — this is how you respond to a disruptive event.
- Business continuity (BC) is focused on mission-critical services that your business needs in order to properly function. It is about services and putting users back to work.
Assume you are using Gmail for sending and receiving emails within and outside your organization. A disaster happened due to whatever reason, and all servers are not available. To give more illustrative examples of DR and BC, have a look at the below:
Disaster recovery is a part of business continuity planning, and both expressions are used as BCDR in the industry. Both answer the “what if a disaster happened?” question and together determine what steps you need to take to ensure business continuity.
Business continuity key metrics – RTO and RPO
Recovery Time Objective and Recovery Point Objective are two core parameters that must be considered when planning for BC:
- Recovery Time Objective (RTO) – the maximum acceptable length of time that your application can be offline from when a disaster is declared. This value is usually
defined as part of a larger SLA. - Recovery Point Objective (RPO) – the maximum acceptable length of time during which data might be lost due to a disaster event. Note that this metric describes the length of time only: it does not address the amount or quality of the data lost.
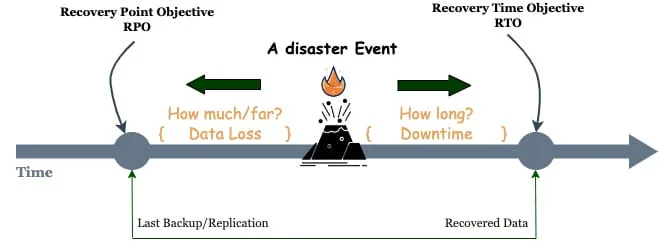
RTO and RPO metrics can differ from one organization to another but should be defined with a business priority to ensure data availability. This can depend on several factors from an organization’s size to its business type, structure, existing in-house resources and other parameters. However, the smaller RTO and RTO values correspond to a higher cost in terms of resources spending, application complexity and operation.
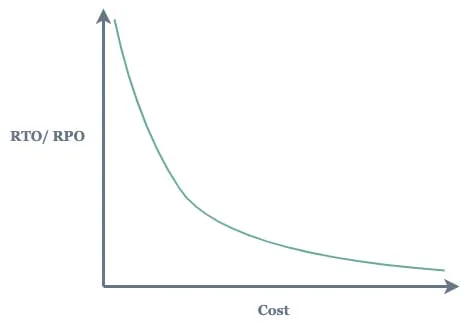
The cost of disaster recovery solutions grows exponentially as RPO and RTO requirements get closer to zero. RTO and RPO values typically roll up into another metric: the service level objective. SLO is a key measurable element of an SLA, although SLAs and SLOs are often conflated:
- SLA is the entire agreement that specifies what service is to be provided, how it is supported, times, locations, costs, performance, penalties, and responsibilities of the parties involved.
- SLOs are specific, measurable characteristics of the SLA, such as availability, throughput, frequency, response time, or quality.
An SLA can contain many SLOs. RTOs and RPOs are measurable and should be considered SLOs.
Why Google Cloud?
The cost associated with fulfilling RTO and RPO requirements when implementing DR can be highly reduced on Google Cloud compared to traditional on-premise, and easier to implement.
Many elements need to be considered when planning traditional on-premise DR, including:
- Compute and storage resources – designed to provide the required performance and scalability.
- Network infrastructure – designed to provide reliable connectivity within the infrastructure and between two data centers.
- Internet and bandwidth – to provide remote access to the secondary datacenter with the planned bandwidth.
- Security – designed to ensure the protection of the physical and digital assets
- Colocation/ data center facility – for all needed IT infrastructure, including equipment and staff.
The disadvantages of traditional on-premise DR include:
- Complexity — a local data center recovery site can be complex to manage and maintain.
- Costs — setting up and maintaining a local site can be time consuming and highly expensive.
- Scalability — resource expansion requires following a traditional procurement cycle, which is not agile and costs a lot of time and money.
Google Cloud Platform helps in overcoming most if not all of these challenges and disadvantages. As well, GCP offers multiple tools and capabilities that allows organizations to efficiently plan their disaster recovery. Undoubtedly, there are certain benefits of DR in GCP, such as:
- Affordable cost — GCP services follow a pay-as-you-use pricing model.
- Accessibility — You’ll be able to access your system from any location.
Common DR patterns
The diagram below shows the DR patterns that are considered on Google Cloud. Different RTO and RPOs indicate how readily a system can recover when something goes wrong.
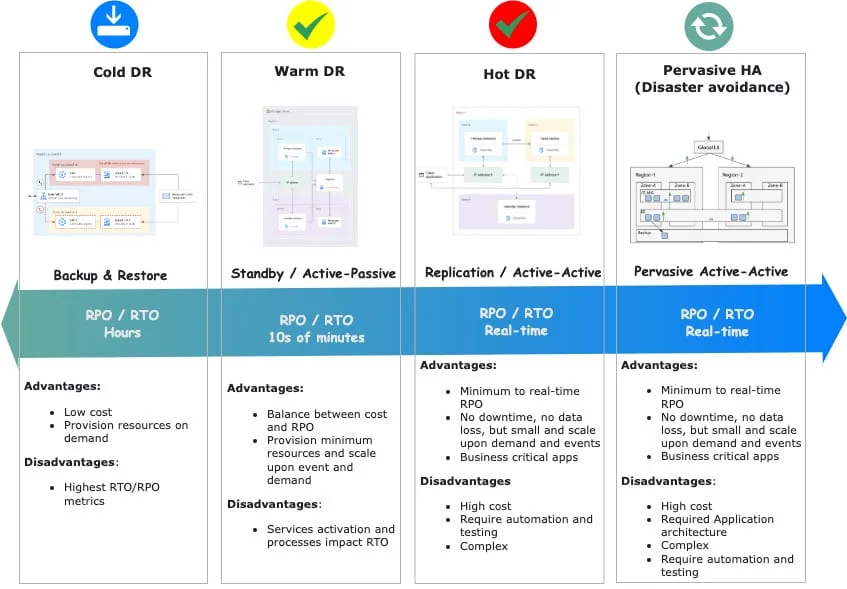
From left to right, patterns become more resilient and more costly. The naming refers to data temperature and how ready it is to be used by compute infrastructure on the secondary region (or zone).
Pervasive HA is HA between regions with transparent failover and load balancing. Customers may use a different terminology, for example, Geo HA, Active/Active, Disaster Avoidance and Business Contingency Group.
Architecture of the DR Patterns
A deep dive into DR patterns and building blocks are beyond the scope of this post. For now, let’s look at examples of the architecture of the various DR patterns.
Cold DR
Below is an example of an architecture for cold DR patterns, moving a VM instance in a new zone (backup-and-restore).
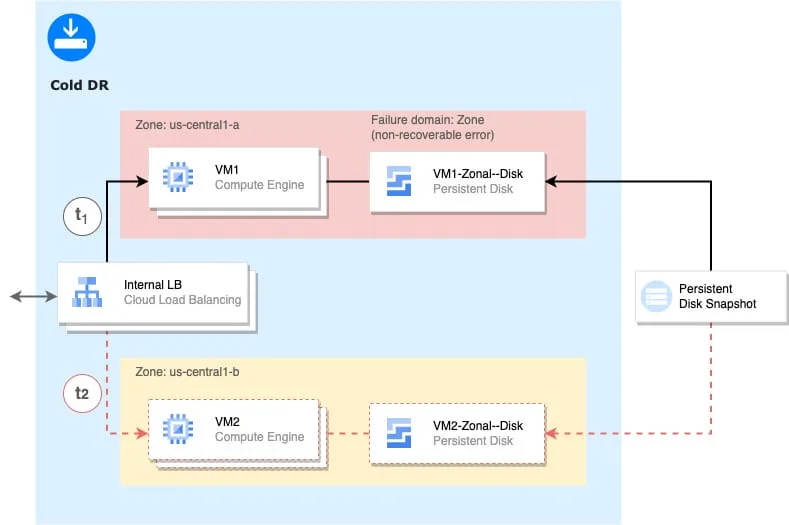
The simplest approach to resilience with zonal resources and recovery through snapshots with sets of building blocks has been selected to perform zone DR with zonal disks and snapshots:
- Zonal managed instance groups
- Zonal persistent disks
- Snapshots of persistent disk attached to VM1
- Internal LB VIP as application entry point, to sidestep potential issues with VM IP reuse
Recovery operations are performed by:
- Creating persistent disks and VM2 from snapshots in second zone
- Booting up VM2 and adding to instance Internal LB group
Synchronous replication between dual zone (active-standby) setup is used to achieve zone DR.
Warm DR
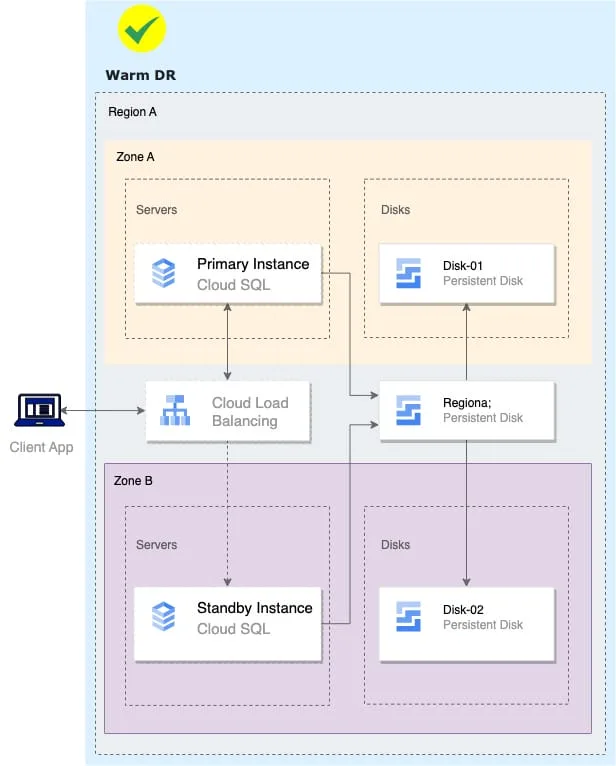
To improve RPO, regional resources can be leveraged to avoid snapshot-based restore operations. This could require:
- Usage of managed services such as Cloud SQL with native replication features
- Regional Persistent Disks with synchronous replication
Depending on the setup this pattern, recovery operations are performed by:
- Activating the standby instance in the secondary zone
- Reactivating a secondary instance in the primary zone when it becomes available
Hot DR
Synchronous replication between dual zone (active-active) setup is used to achieve zone DR.
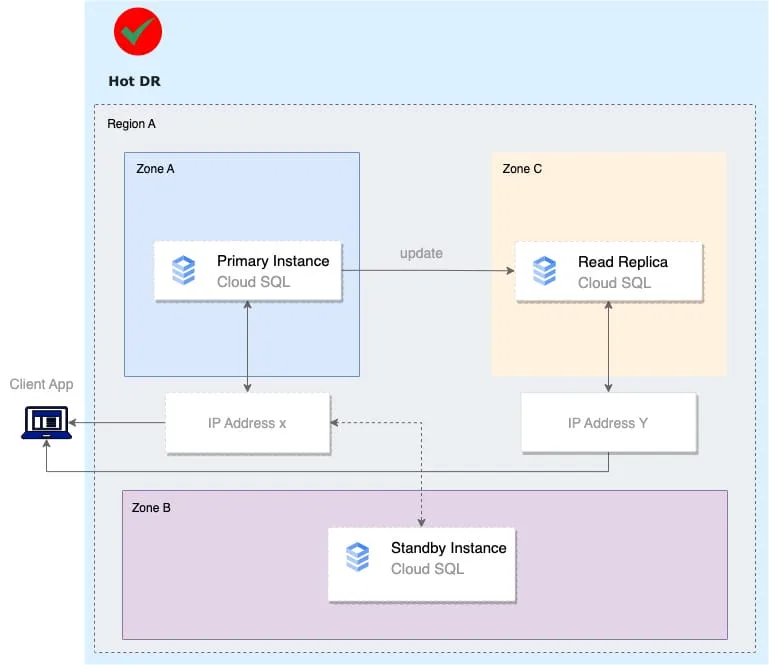
In order to improve RPO and even leverage three zones, regional resources can be used to avoid snapshot-based restore operations. This could require:
- Usage of managed services such as Cloud SQL with native replication features
- Regional Persistent Disks with synchronous replication
Depending on the setup this pattern, recovery operations are performed by:
- Promoting the read replica in the secondary zone
- Reactivating a secondary instance in the primary zone when it becomes available
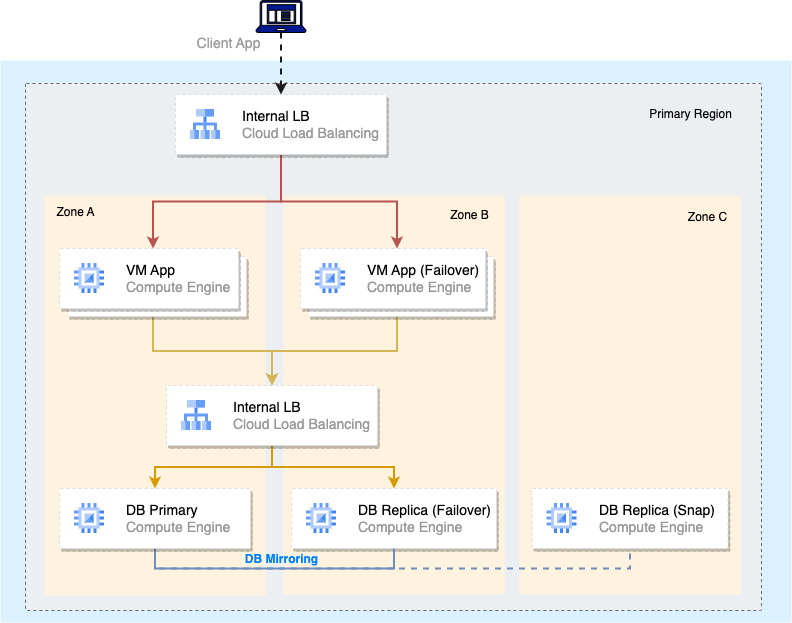
To achieve dual region resilience combined with synchronous and asynchronous replication, this could require:
- Database mirroring mechanisms in primary region with standby instances in the DR region
- Dedicated DB instance for Database snapshots
Recovery operations are performed by:
- Database failover (Secondary to Primary or Snapshot based)
- Internal Load Balancers
Pervasive HA
In the journey to fully leverage cloud-native features, there is the possibility of moving from a recovery to a disaster-avoidance mentality. This leverages cloud constructs and active-active services where multi-region and multi-zone resilience can be enabled:
- Regional MIGs and active-active front-ends across regions
- DNS based or Global Load Balancing to distribute user traffic
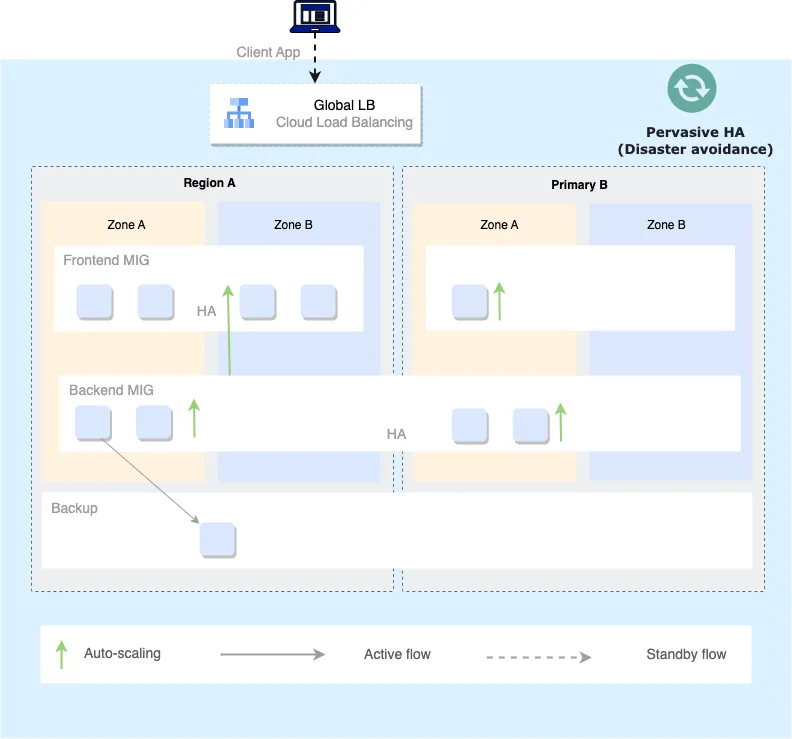
This setup would minimize or avoid manual recovery steps, achieving HA regardless of the failure radius, by leveraging:
- Active-active front-end and back-end services
- Managed multi-regional services (for example, Cloud Spanner or Cloud Storage)
- Auto-scaling to increase capacity in the secondary zone in case of failure
Final words
Disaster events pose a threat to your workload availability but, by using Google Cloud services, you can mitigate or remove these threats. By first understanding business requirements for your workload, you can choose an appropriate DR pattern. Then, using Google Cloud services, you can design an architecture that achieves the recovery time and recovery point objectives your business needs.
Related Resources
All Resources

Get in touch
There are many ways of “doing cloud” but not all of them will future-proof your business. We can devise an approach that will. Talk to us today – you have nothing to lose but the guesswork.
Contact Us